James LimThe Art Of: Getting Remote Engineers to Report BlockersI manage multiple platform-ish teams, and I make it a point to show up in the office every day. I want to make sure that I am available to…2 min read·Feb 3, 2024----
James LimMy Take On ValuesMost values are cringe. They are corporate-sounding and bland truisms that cannot be used to guide teams or set direction. We can do…4 min read·Jan 28, 2024----
James LimStop Using MTTR for SoftwareWe need to measure our incidents. - me several times, usually after a bad outage.6 min read·Dec 3, 2023----
James LimThe Innovative Potential of Whys and Why NotsWhy are we not using Cassandra?3 min read·Aug 20, 2022--1--1
James LimNetwork Security @ Modern TreasuryExcerpt from a journal entry at Modern Treasury.1 min read·Mar 12, 2022----
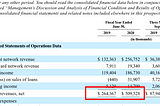
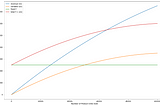
James LimPractical Finance for Software Engineering: Part 3 - Understanding Efficiency(Read Part 2.)4 min read·Sep 26, 2021----
James LimPractical Finance for Software Engineering | Part 2: Understanding Growth(Read Part 1.)3 min read·Aug 28, 2021----
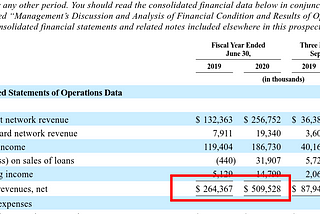
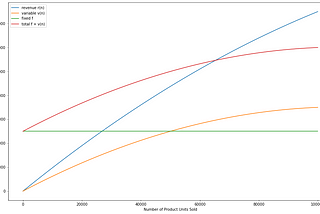
James LimPractical Finance for Software Engineering | Part 1: Understanding Variable Costs and Fixed CostsOr “Finance Wants You to Give a Forecast and What You Can Do About It.”5 min read·Aug 21, 2021----
James LimWhat I Learned About Recruiting Security EngineersI have been building a security engineering team for the past 9 months. Here are a few things I learned.4 min read·May 1, 2021--1--1